Synthetic Data: The Next Frontier of AI and Business Intelligence

Synthetic Data: The Next Frontier of AI and Business Intelligence
1. Introduction
Every AI system lives and dies by the quality of its data.
Yet, in a world governed by GDPR, data scarcity, and privacy ethics, collecting massive, high-quality datasets has become one of the greatest challenges in technology.
Enter synthetic data — information created entirely by artificial intelligence that mimics real-world data but contains no real personal details.
It looks real, behaves real, and powers machine learning just like the real thing — but without the limitations of ownership, cost, or compliance risk.
Synthetic data is no longer a research concept.
It’s becoming a billion-dollar industry transforming how companies build, test, and deploy intelligent systems.
2. What Is Synthetic Data?
Synthetic data refers to artificially generated information — produced by algorithms rather than collected from real-world events.
It can represent any type of data:
- Images: Generated by diffusion models or GANs for computer vision.
- Text: Created by large language models (LLMs).
- Tabular data: Simulated financial, healthcare, or demographic records.
- Sensor data: Artificial IoT streams for testing hardware or robotics.
The goal is simple but powerful:
To create statistically realistic datasets that preserve the patterns and behavior of real data without revealing the originals.
3. Why Synthetic Data Is Exploding Now
The rise of synthetic data is driven by three converging forces:
1. Data Privacy Regulations
Strict laws like GDPR, CCPA, and the EU AI Act make it increasingly difficult to use real user data for model training. Synthetic data solves this by being 100% anonymized and compliant by design.
2. Data Hunger in AI
Modern AI models — especially deep learning and generative AI — require enormous amounts of diverse data. Synthetic data provides infinite scalability without the cost or legal burden of real-world collection.
3. Advances in Generative AI
Thanks to diffusion models, GANs (Generative Adversarial Networks), and transformers, synthetic datasets can now replicate the statistical complexity of human behavior, voice, and vision — almost indistinguishably.
4. How Synthetic Data Works
Creating synthetic data involves three main steps:
1. Modeling Real-World Patterns
An AI model learns the structure of real datasets — such as correlations, outliers, and variable distributions.
2. Generating New Data
Using generative algorithms (e.g., GANs, VAEs, or diffusion models), the system creates new samples that mirror the learned patterns.
3. Validation
Generated data is tested against original datasets to ensure fidelity, diversity, and privacy compliance.
The result: high-quality, realistic data ready for model training, analytics, or software testing — without exposing sensitive information.
5. Applications Across Industries
Finance
Banks and fintechs use synthetic data to simulate customer transactions, detect fraud, and test algorithms without breaching confidentiality.
Healthcare
Synthetic patient data allows research and AI diagnostics without exposing private health records. Startups like Syntegraand MDClone are leading the charge.
Retail and Marketing
Companies generate behavioral data to train recommendation systems or personalize user journeys without tracking individuals.
Autonomous Vehicles
Self-driving car models train on billions of AI-generated road scenarios — far beyond what can be captured in the real world.
Software Testing
Developers use synthetic data to test apps, APIs, and databases in conditions that mimic real usage but with zero real customer data.
6. Synthetic Data in Business Intelligence
Traditional business intelligence relies on historical data — which is limited, outdated, or incomplete.
Synthetic data, by contrast, enables scenario simulation and predictive modeling beyond existing records.
Companies can now:
- Simulate market reactions before launching a product.
- Model risk scenarios that never happened before.
- Test “what if” hypotheses safely at scale.
In essence, synthetic data transforms BI from analysis to anticipation — shifting business from reactive to proactive.
7. Benefits of Synthetic Data
AdvantageDescriptionPrivacy & ComplianceNo real users, no risk of exposure.Cost EfficiencyGenerate data at scale without collection costs.SpeedTrain and test faster with unlimited data.Bias ReductionBalance datasets by generating underrepresented classes.InnovationTest scenarios impossible in real life.
Synthetic data doesn’t just replicate — it enhances.
It lets businesses model possibilities that reality hasn’t provided yet.
8. The Business Case for Synthetic Data
The world’s largest companies are already investing heavily in synthetic data infrastructure:
- Google DeepMind uses synthetic environments for reinforcement learning.
- NVIDIA Omniverse simulates digital twins for industrial optimization.
- Meta and OpenAI train multimodal models on synthetic datasets.
For software companies and data-driven enterprises, synthetic data offers three critical business advantages:
1. Risk Reduction
AI teams can train models without legal or reputational exposure from real data breaches.
2. Product Velocity
Faster iteration cycles — because data creation no longer depends on external collection.
3. Competitive Differentiation
Early adopters of synthetic data can create predictive, privacy-first products ahead of regulation curves.
9. Challenges and Ethical Considerations
Despite its potential, synthetic data raises critical questions:
- Fidelity vs. Originality: How realistic is too realistic? Perfect replicas can inadvertently reproduce real identities.
- Bias Amplification: If the original dataset is biased, synthetic versions can multiply those biases.
- Trust and Transparency: Businesses must disclose when insights or models rely on synthetic data.
The future of synthetic data depends not only on innovation — but on responsibility.
10. The Future: Generative Intelligence for Data
By 2030, experts predict that 70% of all AI training data will be synthetic.
As generative models evolve, they won’t just imitate real data — they’ll invent new realities for simulation, discovery, and creativity.
Imagine a world where:
- Digital twins of entire cities simulate traffic, energy, and climate flows in real time.
- AI systems test business decisions before they’re made.
- Products are optimized in virtual environments long before they reach the market.
Synthetic data is not the end of reality — it’s the beginning of augmented reality for intelligence.
Conclusion
In a data-driven economy, access to information defines success — but in the quantum era of AI, creating informationwill define leadership.
Synthetic data empowers businesses to move beyond limitations: no more waiting for data collection, no more compliance bottlenecks, no more blind spots.
For software companies, startups, and innovators, it’s the ultimate accelerator — turning imagination into measurable intelligence.
Because in the future of AI, the question won’t be how much data you have,
but how smart the data you create.
Przeglądaj inne artykuły

Why Most Marketplaces Fail: The Hidden Challenges Behind Scaling Supply and Demand
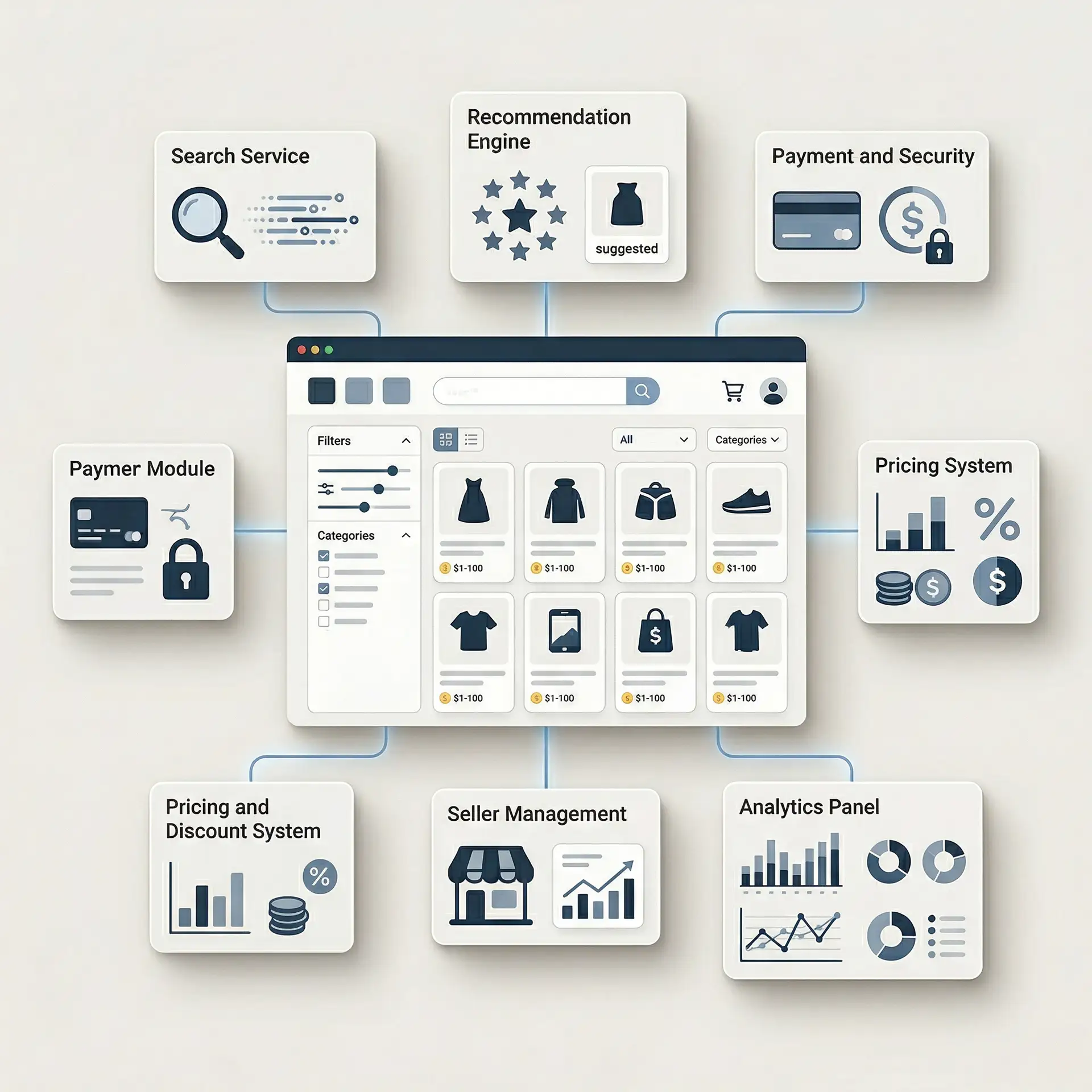
Composable Marketplaces: Building Flexible, Scalable Platforms for Modern Commerce
The New Marketplace Economy: How Platforms Are Evolving into Intelligent, Scalable Ecosystems

From Search to Intent: How AI Is Rewriting Marketplace Discovery

AI-Driven Marketplaces: Real-Time Offer Matching as a Competitive Advantage

Category Depth vs Category Breadth: The Real Economics Behind Marketplace Expansion

Liquidity Is Not Volume: The Structural Mistake That Kills Marketplaces

The Take Rate Trap: Why Raising Commissions Is the Fastest Way to Kill a Marketplace

When to Fire Sellers: Why the Best Marketplaces Grow Faster by Shrinking Supply

Marketplace Support Costs: The Hidden Margin Killer No One Models

Tiered Pricing Without Backlash: How to Monetize Sellers Without Killing Growth

Seller Segmentation: The Missing System Behind Profitable Marketplaces

Why Most Marketplaces Die at €1–3M GMV (And How to Avoid It)
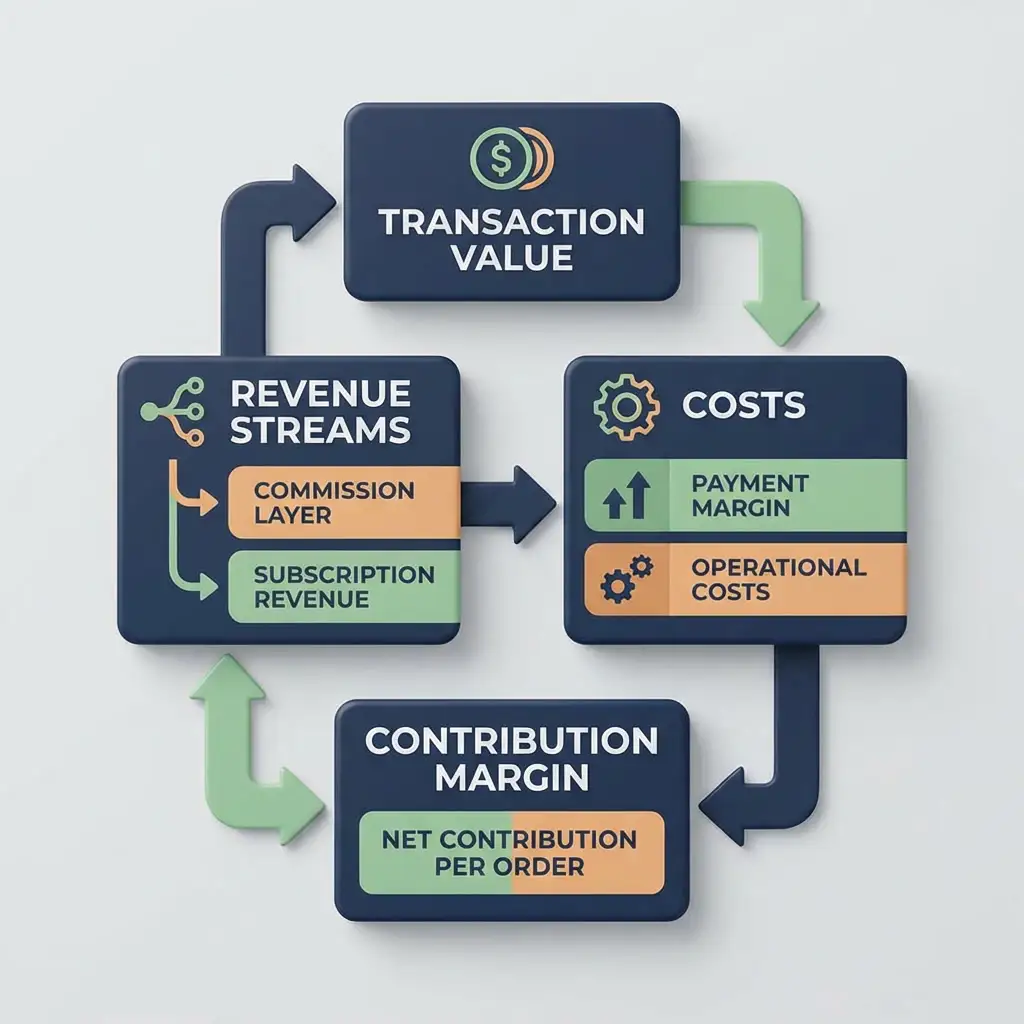
Marketplace Unit Economics: When Growth Actually Becomes Profitable

How High-Margin Marketplaces Actually Make Money (Beyond Commissions)

Algorithmic Middle Management: How Software Replaces Control Layers

The Rise of Internal Software: Why the Most Profitable Digital Products Are Built for Companies, Not

Decision-Centric Software: Why the Real Value of Digital Products Is Shifting from Features to Decis

Software That Never Launches: Why Continuous Evolution Is Replacing Releases and Roadmaps

Digital Products Without Users: When Software Works Entirely Machine-to-Machine

Unbundled Platforms: Why the Future of Digital Products Belongs to Ecosystems, Not Single Applicatio

Silent Software: Why the Most Valuable Digital Products of the Future Will Be the Ones Users Barely

Cognitive Commerce: How AI Learns to Think Like Your Customers and Redefines Digital Shopping

Predictive UX: How AI Anticipates User Behavior Before It Happens

AI-Driven Product Innovation: How Intelligent Systems Are Transforming the Way Digital Products Are

Adaptive Commerce: How AI-Driven Systems Automatically Optimize Online Stores in Real Time

Zero-UI Commerce: How Invisible Interfaces Are Becoming the Future of Online Shopping

AI Merchandising: How Intelligent Algorithms Are Transforming Product Discovery in Modern E-Commerce

Composable Commerce: How Modular Architecture Is Reshaping Modern E-Commerce and Marketplace Develop

Context-Aware Software: How Apps Are Becoming Smarter, Adaptive, and Environment-Responsive

AI-Driven Observability: The New Backbone of Modern Software Systems

Hyper-Personalized Software: How AI Is Creating Products That Adapt Themselves to Every User

Edge Intelligence: The Future of Smart, Decentralized Computing

AI-Powered Cybersecurity: How Intelligent Systems Are Redefining Digital Defense

Modern Software: How Our Company Is Reshaping the Technology Landscape

From Digital Transformation to Digital Maturity: Building the Next Generation of Tech-Driven Busines

AI Agents: The Rise of Autonomous Digital Workers in Business and Software Engineering

Quantum AI: How Quantum Computing Will Redefine Artificial Intelligence and Software Engineering

Design Intelligence: How AI Is Redefining UX/UI and Digital Product Creativity

How Artificial Intelligence Is Transforming DevOps and IT Infrastructure

AI Observability in Production: Monitoring, Anomaly Detection, and Feedback Loops for Smart Applicat

Low-Code Revolution: How Visual Development Is Transforming Software and Marketplace Creation

Composable Marketplaces: How Modular Architecture Is the Future of Platform Engineering

AI-Powered Storyselling: How Artificial Intelligence Is Reinventing Brand Narratives

The Era of Invisible Commerce: How AI Will Make Shopping Disappear by 2030

From Attention to Intention: The New Era of E-Commerce Engagement

Predictive Commerce: How AI Can Anticipate What Your Customers Will Buy Next

Digital Trust 2030: How AI and Cybersecurity Will Redefine Safety in the Digital Age

Cybersecurity in the Age of AI: Protecting Digital Trust in 2025–2030

The Future of Work: Humans and AI as Teammates

Green IT: How the Tech Industry Must Adapt for a Sustainable Future

Emerging Technologies in IT: What Will Shape 2025–2030

Growth Marketing – A Fast-Track Strategy for Modern Businesses

AI SEO Tools – 5 Technologies Revolutionizing Online Stores

AI SEO – How Artificial Intelligence Is Transforming Online Store Optimization

Product-Led Growth – When the Product Sells Itself

Technology in IT – Trends Shaping the Future of Business and Everyday Life

Marketplace Growth – How Exchange Platforms and E-commerce Build the Network Effect

Edge Computing – Bringing Processing Power Closer to the User

Agentic AI in Applications – When Software Starts Acting on Its Own

Neuromorphic Computers and 6G Networks – The Future of IT That Will Change the Game

Meta Llama 3.2 – The Open AI That Could Transform E-Commerce and SEO

AI Chatbot for Online Stores and Apps – More Sales, Better SEO, and Happier Customers

5 steps to a successful software implementation in your company

Innovative IT solutions — why invest now?

Innovative software development methods for your business

5 steps to successfully implement technological innovation in your company